PINN
PINN初探
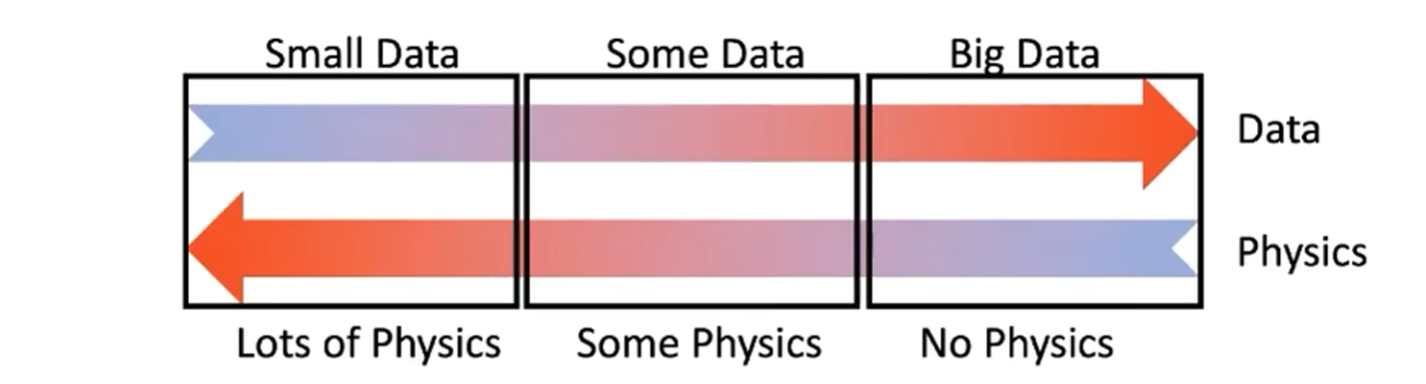
 神经网络正则项的存在可以帮助抗噪声
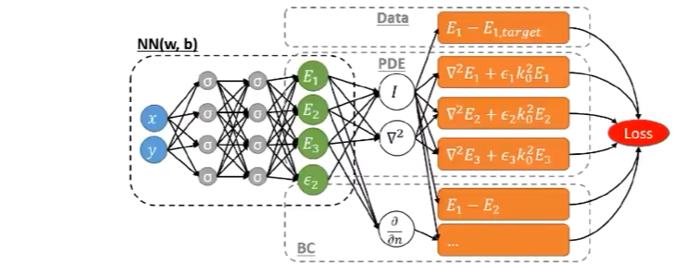
神经网络正则项的存在可以帮助抗噪声 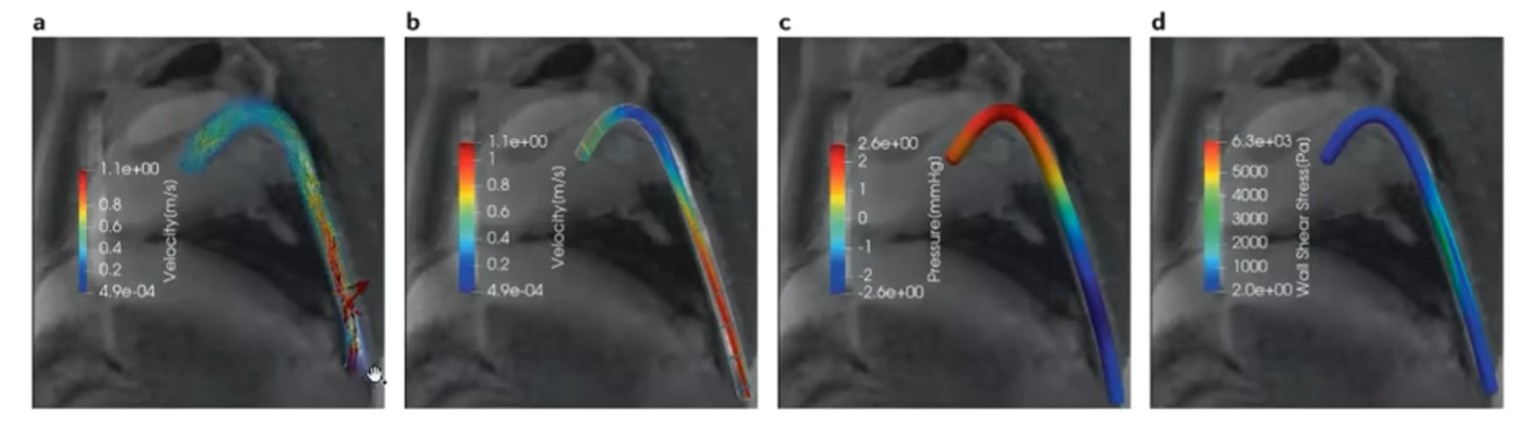 反问题求解往往需要大量算力
而且求解中自动微分有着天然的优势(无需细网格有限元
反问题求解往往需要大量算力
而且求解中自动微分有着天然的优势(无需细网格有限元 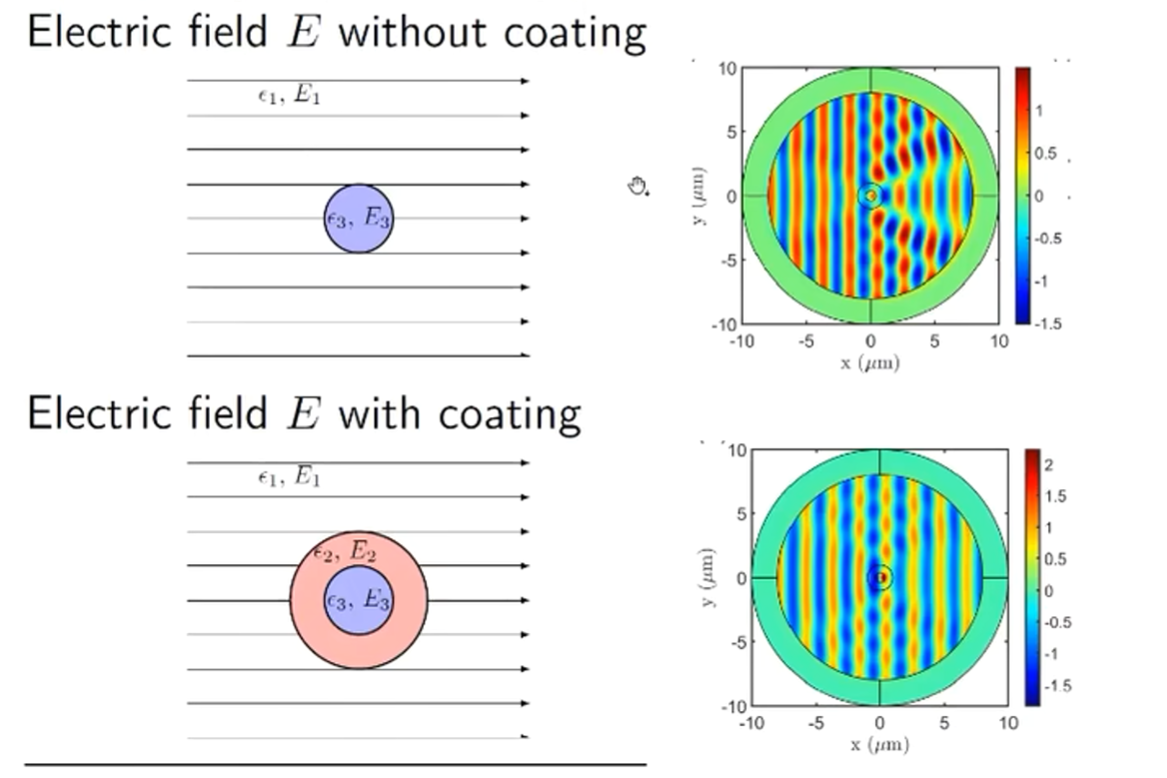
背景
实际上,针对复杂静/动力学系统模型化主要有 两个途径。第一个是基于理论的模型架构,即根据物 理问题的控制方程,建立理想的系统描述。这种模型 通常需要研究者对物理过程有深刻的理解,并将其转 化为数学模型,现行的湍流模型大都是采用这个途 径。第二个则是数据驱动方法,即根据系统仿真或试 验中的样本数据,直接构造黑箱或灰箱模型。近年 来,随着计算机性能和精细化流动测试手段的发展, 研究者逐步能够获得高精度、高时空分辨率的流场信 息,或者直接通过开放的平台(如http://turbulence. pha. jhu.edu/)获取。如何高效地利用这些大数据,从 中提取出关键信息,并指导流体力学的发展,已经成 为研究者关注的焦点。作为处理和分析数据的主要 手段,数据挖掘、统计学习和机器学习等技术,则为开 展此类研究提供了重要基础。机器学习通过一些算 法从数据中建立模型,使之具备一定的判断和预测能 力。常用的算法有径向基神经网络(RBFNN)、随机 森林(RF)、支持向量机(SVM)和神经网络(NNs)等。 这些算法已广泛应用于语音和图像识别、信号处理以及降阶处理等领域。
机器学习在湍流研究中的快速发展在一定程度上也得益于诸多广泛使用的开源平台。目前,TensorFlow、Keras、Theano以及Matlab等平台为开展学习工作提供了有力支持。这些平台大都内嵌了多种学习框架供用户选用,如RBFNN、RF以及更复杂的深度神经网络(DNN)和卷积神经网络(CNN)等。同时,模型的超参数优化可采用随机梯度下降(SGD)、动量随机梯度下降(SGDM),以及Adam算法等实现。此外,基于CPU或GPU的并行算法缩短了湍流大数据的模型优化过程。这些开发平台的使用大大提高了研究者的工作效率,便于迅速开展并推进研究工作,而且,代码的通用性也有助于研究者之间的相互交流和探讨。
缺点
由于模型是数据驱动的,因此,模型的 性能在本质上是由所选取的训练数据决定的,模型往 往在那些与训练数据差异较大的预测数据中表现较 差。这就要求研究者谨慎地选取模型构建对象和方 法以尽量提高模型的泛化能力。
提升智能赋能流体力学的可解释性,探索 流体力学新的物理内涵和科学认知。以神经网络 为代表的黑箱模型和统计机器学习方法暴露出缺 乏解释性、稳定性差等不足之处,特别是近年在流 体力学机器学习研究中表现得特别突出,已经成 为智能化方法和模型应用的瓶颈。如何有机结合 现有流体力学知识和大数据,有机结合符号学习 和统计学习这两类不同的机器学习方法,来提高 智能模型的可解释性,进一步探索流体力学更加 基本的物理内涵和科学认知,是未来需要着重加 强的方向。
AI in Fluid Mechanics
特别是20世纪80年代以来,CFD 技术的 蓬勃发展,极大降低了流体力学分析难度和设计 成本。然而,由于湍流、转捩等问题的复 杂 性,仍 有很多基础性和工程应用问题亟待解决。对海量、精细化测量数据的信息提取和特征分析为挖掘复杂流动机制提供 了新的技术支撑。
就流体力学研究而言,其途径包括理论分析、 数值方法以及实验技术。理论分析和数值方法包 括理论解、理论模型、标度理论以及高精度的数值 格式、高效计算方法等。目前来看,这些基础性研 究成果的发现/提出大多仍是直接依赖于人类的 智慧。流体力学通过计算机或在试验中所产生的 数据是天生的大数据,如何通过人工智能方法来 利用这些大数据,通过机器学习来缓解甚至替代 理论/方法层面对人脑的依赖,是一个非常不错的 方向。
流体力学虽然是一个古老的学科,但至今仍是一个对数学和物理学基础依赖很强的工程科学。没有较好数理基础的工作者,很难得心应手地从事流体力学研究,尤其是在理论和数值方面。即使是流体力学专业研究者,也会觉 得方程推导和公式反演枯燥乏味。流体力学学科的发展一直都是依赖于基本方程、基本模型和计算方法。可以说,前人建立的基本理论、模型和方法是流体力学工程应用和进一步理论发展的前提。在大数据时代,通过人工智能方法来构建复杂流体系统的控制方程和基本模型,并发展新型的数值方法提高精度和鲁棒性,减少人工干预和计算成本